Goals - Scalability
가장 중요한 목적 중 하나이다.
분산 시스템은 리소스가 서로 다 흩어져있는 상황에서 많은 사용자를 서포트할 수 있으면 좋은 시스템이다.
Measurement of scalability
scalability는 세 가지 측면이 있다. 세 가지 모두에서 scalable한 시스템은 좋은 시스템이지만 그렇게 되기 쉽지 않다. 보통 세 가지 중 두 가지 정도에서 scalable한 시스템을 만든다.
1) Size
여기서 규모는 사용자 수 즉 사용자 규모 측면과 분산 시스템 컴포넌트 측면에서의 규모에 대한 scalability를 말한다. 많은 수의 컴포넌트로 구성하면 규모있는 분산시스템이 된다. 결국 같은 이야기다. 많은 수의 사용자를 감당하려면 많은 수의 컴포넌트가 필요하다. 분산시스템의 구조를 고려할 때 규모 측면의 확장성을 제공하려면 중앙 집중식 구조보다 분산화된 구조를 사용하는 것이 확장성이 좋다.
(1) 중앙집중식 서비스
중앙집중식 서비스의 경우 서비스를 한 곳에서 제공하기 때문에 사용자가 많으면 많은 리퀘스트가 한 서버에 집중되게 된다. 이로 인해 bottleneck 문제가 발생한다. 많은 경우 서버에 렉이 걸리는 경우는 이에 해당된다. 서버 머신이 컴퓨팅과 스토리지 capacity가 아무리 좋아도 커뮤니케이션 측면 때문에 이러한 문제가 발생한다.
(2) 중앙집중식 데이터
분산 시스템이 제공하는 서비스 중 데이터 서비스가 있을 수 있다. 사용자 데이터나 사용자가 필요로하는 데이터를 분산시스템 서버쪽에 보관을 하고 있는데 이러한 데이터가 한 서버에 집중되어 저장이 되어있을 경우 데이터의 가용성(availbility)이 매우 떨어질 수 있다. 서버가 고장나면 데이터 전체가 날라가는 등 single point of failure 문제가 발생할 수 있다.
DNS의 경우 여러 서버에 계층적으로 분산되어 관리되고 있다. 만일 DNS가 한 서버에 집중되어 관리되고 있다고 가정하면 여러 문제가 발생한다. 우선 네트워크를 사용하는 모든 서비스가 느려질 것이다.
(3) Centralized algorithm
분산 시스템을 개발할 때 해당 알고리즘 자체가 중앙집중식일 수도 있고 분산 알고리즘일 수도 있다. 중앙집중식 알고리즘은 input data가 한 곳에 다 모여야 하는 것을 의미한다. 따라서 decentralized algorithm을 사용해야 한다.
decentralized algorithm의 경우 아무 머신도 시스템 상태에 대한 완전한 정보를 가지고 있지 않다. 시스템 상태 정보는 위에서 말한 알고리즘을 돌리는데 필요한 인풋 데이터를 말한다. 머신은 자신의 로컬 정보만을 가지고 결과를 낸다. 중앙집중식 알고리즘에 비해 고장이 났을 때 해당 알고리즘만 작동이 안되고 다른 서버들은 각자 알고리즘을 계속 돌릴 수 있다.
그렇다면 decentralized algorithm이 항상 좋은것일까? 모든 것에는 장단점이 있다. decentralized algorithm의 단점은 최적의 결과를 찾기 어렵다는 것이다. 알고리즘의 측면으로 보면 해당 알고리즘이 optimal solution을 얻고자 할 때 centralized algorithm이 더 좋은 solution을 낼 수 있다. decentralized algorithm은 최적의 결과보다 빠른 결과를 얻고자 할 때 좋다. 그리고 다른 단점은 여러 서버가 각자 알고리즘을 돌리고 그 결과를 sync를 맞춰 동작해야 하는 경우가 생긴다. 이때 모든 서버들의 내부 시간 정보가 맞아야한다. 시간 동기화를 잘 해야한다는 추가 조건이 생긴다.
2) Geography
분산 시스템에서 각 서버가 지리적으로 서로 멀리 떨어져 있을 때에도 동일한 퀄리티를 제공할 수 있으면 좋다. 서비스를 요청하는 서버와 클라이언트간의 거리 뿐만 아니라 서비스를 제공하는 서버들 간의 거리도 중요하다. 거리가 멀어지면 멀어질수록 커뮤니케이션 딜레이 때문에 문제가 될 수 있다. 다음과 같은 두 커뮤니케이션을 사용할 경우 딜레이가 커질 수 있다.
(1) Synchronous communication
커뮤니케이션 한다는 것은 떨어져있는 두 노드가 request, reply 패턴이 반복되는 것을 말한다. Synchronous communication이란 클라이언트가 요청을 보냈을 때 서버가 답변을 보내줄 때까지 다른 것을 하지 못하고 block되는 것이다. 반대는 Asynchronous communication이다.
(2) Unreliable, point-to-point communication
LAN환경이 아닌 WAN환경에서는 네트워크를 통한 커뮤니케이션 서비스가 unreliable하다. 받는 쪽에서 패킷이 많아 버퍼가 가득 차는 경우 받은 패킷을 버릴 수 있기 때문에 애플리케이션 입장에서는 라우터단에서 주고받는 패킷이 언제 사라질지 모르기 때문에 TCP 프로토콜을 사용한다. 네트워크 레이어(IP Layer)의 네트워크가 unreliable하기 때문에 그 위에 TCP라는 프로토콜 레이어가 덫씌워진 것이다. 이런 환경에서 메세지를 주고받는다면 메세지가 중간에 사라질 수 있기 때문에 다시 보내야 한다. 그리고 분산 시스템 서비스를 사용하려면 무슨 서비스가 있는지 일단 알아야한다.(Locating a service 문제) WAN환경에서 어디있는지 모를 경우 전체 네트워크로 브로드캐스트해야하므로 네트워크가 혼잡해지는 문제가 발생할 수 있다.
3) Administration
Administ하게 스케일러블하다는 것은 기술적인 측면보다는 정책적인 측면이 강하다. 어떤 하나의 분산 시스템 서비스를 특정 조직에서 관리하는 것이 아니고 여러 조직에서 공동으로 관리하고 서비스해주면 더 좋다. 예를 들어 KT, SKT, LG에서 정책 합의를 통해 어떤 서비스를 공동으로 제공해주겠다고 하면 사용하는 통신사에 상관없이 공통된 서비스를 이용할 수 있고 통신사 변경했을 때 별도의 조치없이 계속 사용할 수 있으므로 사람들 입장에서는 훨씬 편해질 것이다.
(1) Security
하나의 분산 시스템 서비스를 여러 조직에서 관리하기 때문에 보안 측면이 강화되어야 한다.
Scaling techniques
Administration 측면을 제외하고 Size와 Geography 측면에서 Scalibility를 제공하기 위해 다음 세 가지의 기술적 기법이 있다.
1) Hiding communication latency
사용자가 클라이언트 애플리케이션에 액션을 취해서 서비스를 요청했을 때 걸리는 시간을 줄이는 것이다.
(1) Asynchronous communication
Interrupt-based single thread나 multiple threads를 사용하여 구현할 수 있다. 그렇지만 애플리케이션의 경우에 따라 사용할 수 없을 수도 있다. 예를 들어 다른 할 일이 없는 경우 굳이 Asynchronous communication을 사용할 필요가 없다.
(2) Reduce the overall communication
메세지를 보내면 물리적으로 지연을 숨길 수 없으므로 보내지 않아도 되게끔 만든다. 최대한 서버로 요청해서 응답을 받는 횟수를 줄인다. 로컬에서 해결할 수 있는 것은 가능한 한 로컬에서 해결한다. 서버에서 하는 역할이 있을 텐데 필요한 경우 그 부분을 클라이언트에 가져와서 처리한다.
예를 들어 사용자가 입력한 폼의 적합성 형태를 서버에서 검증할 때 각 필드별로 서버에 요청한 후에 그 다음 필드를 검증받는다. 이 때 가능한 한 응답받는 횟수를 줄이기 위해 클라이언트에서 체크한 후에 한번에 데이터를 서버로 보낸다.

다른 예로 java applets이 있다. java applet은 자바로 짠 코드를 독립된 애플리케이션이 아니고 웹 브라우저 상에서 실행할 수 있는 자바 프로그램이다. 웹 브라우저를 돌다 java applets 링크를 누르게 되면 웹 서버에 있는 java applets 코드를 웹 서버에서 돌린 후 결과를 매번 받는 대신 웹 브라우저로 다운한 후 그 코드가 클라우드에서 돌린다. 받는데 까지는 시간이 걸리겠지만 실행속도가 빠르고 서버에서 바로 돌리면 바로 시작하는 시간은 빠르겠지만 실행시간이 느려진다.
2) Distribution
대표적인 예로 DNS가 있다. 사람들이 이해할 수 있는 host name을 기계가 이해할 수 있는 domain name으로 변경해주는 일을 한다. DNS 서버는 전세계에서 사용하는 모든 host name이 있고 그에 mapping되는 ip address가 있다. 전세계적으로 DNS 서버가 한대만 있다면 문제가 많기 때문에 서버가 여러대 있다. 각 서버간에 루트 서버부터 자식 서버로 계층이 있다. distribution는 여러 리소스가 있을 때 그것을 쪼개서 여러 서버에 나눠주는 것이고 replication은 복사해서 여러 서버가 같은 리소스를 관리할 수 있도록 해주는 것이다. DNS는 replication도 사용하지만 주된 기능은 distribution이다.
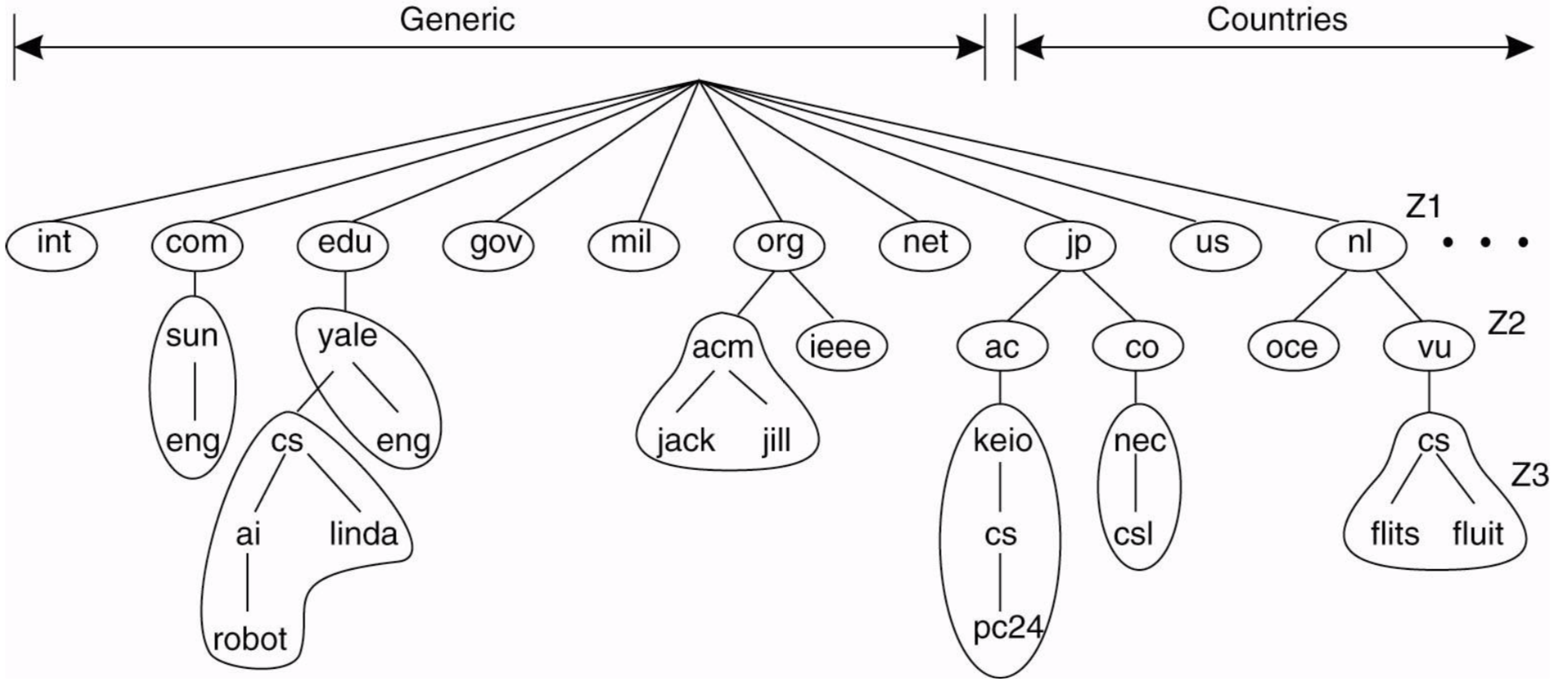
예를 들어, nl.vu.cs.flits라는 리퀘스트가 들어오면 루트부터 해당 서버를 찾는다. 이런식으로 분산되어 처리한다. 위에서 루트부터 찾는다 했는데 웬만해서는 캐싱되어있는 로컬 네임서버에서 처리한다. 그러므로 루트 서버가 전세계에 있는 DNS의 request를 받지는 않는다.
그 다음 예는 WWW이 있다. 전 세계에 웹 서버가 분산되어 있고 각자 나름대로 웹 컨텐츠를 관리하고 있다. 이는 물론 replication 또한 사용하지만 주요한 것은 distribution이다.
3) Replication
replication은 복제하는 것이다. distribution과 달리 replication만의 장점은 resource의 가용성(availability)이 올라가는 것이다. 같은 resource가 여러 곳에 있으므로 이용할 수 있는 확률이 올라간다. 그리고 인기 있는 자원에 대해 복제해서 여러곳에 두면 부하를 분산(load balancing)시킬 수 있다.
(1) Caching
캐싱의 경우 리소스를 요청한 클라이언트 로컬에 저장해두는 것이 캐싱이고 replication은 클라이언트가 아닌 서버가 사용자가 요청하기 전에 복제를 해두는 거이다.
(2) Consistency problems
리소스의 내용이 변경될 수 있으므로 복제된 모든 곳에서 리소스의 내용을 일치시켜야 한다. 분산 시스템 서비스의 종류에 따라 Consistency를 맞춰주는 정책을 잘 사용해야한다. 예를 들어 주식의 경우 시시각각 변화하는 데이터가 중요하기 때문에 매우 작은 범위마다 Consistency 일치 여부를 확인해야하고 다른 경우에는 더 느슨하게 관리해도 된다.
여러 곳에 복제되어 있는 같은 리소스를 동시에 각각 다르게 수정하려고 할 때 충돌 문제가 발생할 수 있다.
4) 정리
Size 측면의 scalability가 상대적으로 가장 해결하기 쉽다. 실제로 쉬운건 아니지만 머신의 성능(capacity)을 높여주면 되기 때문에 상대적으로 쉽다고 볼 수 있다. distribution, replication, and caching을 결합한 형태는 실제로 많이 사용되는 테크닉이다. Administrative scalability는 기술적인 측면이 아니라서 세 가지 중에서 가장 해결하기 어려운 것이다.
'Distributed System > 이론 공부' 카테고리의 다른 글
| 분산시스템) 아키텍쳐 (0) | 2020.08.15 |
|---|---|
| 분산시스템) 분산시스템 종류 및 Pitfalls (0) | 2020.08.15 |
| 분산시스템) 목표(3) - Openness (0) | 2020.08.15 |
| 분산시스템) 목표(2) - Distribution transparency (0) | 2020.08.15 |
| 분산시스템) 목표(1) - Making resources accessible (0) | 2020.08.15 |

