Server
General design issues
client의 경우 사용자 편의에 주안점을 둔다면 서버의 경우 서비스를 제공하는 입장이므로 performance가 주된 디자인 이슈가 된다.
Organizing servers
(1) Iterative server
서버 프로세스가 하나밖에 없어서 순차적으로 다 한다는 의미이다. single process.
(2) Concurrent server
다중 스레드를 사용하여 concurrent 하게 task를 수행할 수 있도록 구성한다. iterative server보다 performance가 더 좋다.
멀티스레드나 fork를 통하여 새로운 프로세스 만들어서 할 수 있다. fork를 사용하는 대표적인 예는 UNIX systems이 있다. 메인 데몬 프로세스가 사용자로부터의 요청을 기다리고 있다가 사용자 요청에 따라 요청을 수행할 프로세스를 만든다. shell 프로세스의 역할이 그런 것이다.
Client 편의성
서버는 클라이언트에게 가능한 빨리, 편하게 서비스를 요청할 수 있도록 하면 좋다. 여기서는 퍼포먼스 측면보다 클라이언트의 편의성 측면에서 이야기를 할 것이다. 클라이언트는 어떻게 서비스의 엔드포인트를 알게 되는걸까? 엔드포인트는 서버별로 포트번호가 나뉘어 있어 서버 머신에서 돌아가는 여러 서버 프로세스를 구분해주는 것이다. 서버 머신과 서버 머신을 구분해주는 것은 네트워크 주소이다. 서버 머신에서 돌아가는 서비스를 포트 번호로 구분한다. 클라이언트는 해당 서버의 주소와 포트번호를 알면 해당 프로세스로 연결할 수 있다. 이런 주소와 포트번호를 알아서 연결하는 것은 클라이언트 쪽 미들웨어가 한다.
(1) 표준 포트번호
예로 FTP (21), HTTP (80) 등이 있다.
(2) 포트번호가 바뀌는 경우
To dynamically assign end points on demand
클라이언트 쪽 미들웨어는 서버의 포트가 바뀔 수도 있는 상황에 대비하여 사용해야 할 포트 번호를 서버에게 먼저 물어봐야 한다. 서버의 포트번호가 바뀔 경우 클라이언트에게 바뀐 포트번호를 어떻게 알려줄 수 있을까. 서버 머신에 서비스를 제공하는 일반 서버 프로세스와 별도의 super daemon process를 두고 일반 서버 프로세스가 현재 사용하는 포트를 데몬에 등록해둔다. 데몬은 포트번호만 관리하는 포트번호 관리 서비스이다. 클라이언트는 우선 포트번호는 데몬에게 물어본다. 그럼 데몬의 포트번호는 어떻게 알까 데몬의 포트번호는 잘 바뀌지 않는 well-known 번호를 사용한다고 가정한다.
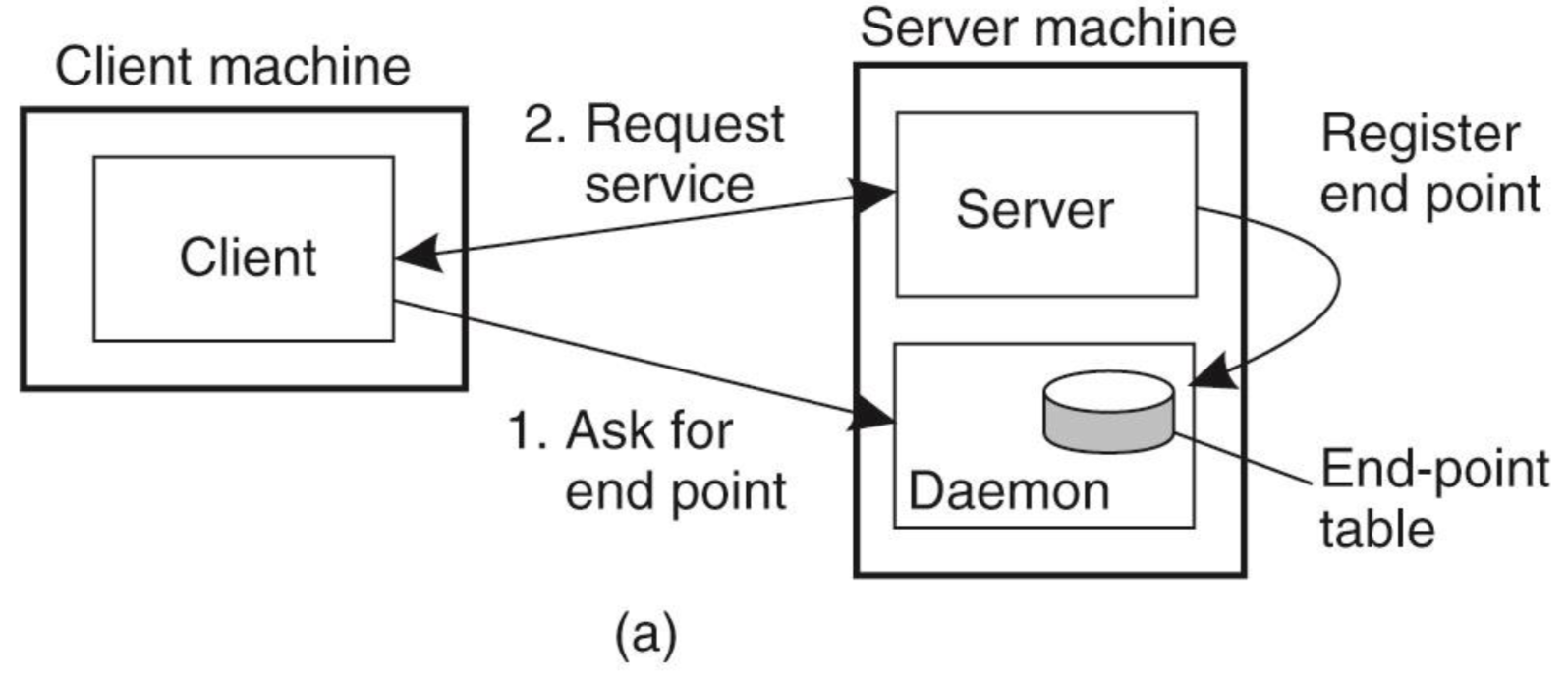
자원낭비가 일어나 비효율적이라는 단점이 있다. super server와 server가 모두 계속 돌고 있다. 이를 해결하기 위해 UNIX에서는 super server에 요청이 들어왔을 때에만 fork를 통해 서비스를 제공해줄 서버 프로세스를 새로 만들어준다. 다 끝나면 해당 프로세스는 다시 없어진다. UNIX의 inetd daemon이 이런 super server 역할을 하는 것이다.

(3) Interrupt
클라이언트가 서버에 어떤 task를 요청한 후에 서버가 해당 task를 수행 중인데 중간에 클라이언트가 서버에 interrupt를 요청할 수 있을까? 예를 들어 채팅 앱에서 실수로 보낸 메시지를 지우는 것이 있다. 메일도 비슷한 경우가 있다. 이런 식으로 이미 서버 쪽에 올린 데이터를 지우는 것은 비교적 쉬울 수 있다.
(ㄱ) 클라이언트 끄기
서버가 진행 중인 작업을 중단하고 싶으면 쉬운 방법은 클라이언트를 꺼서 서버와의 연결을 끊는 것이다. 클라이언트를 껐다 켜서 다시 시작하는 방법이다.
(ㄴ) out-of-band data
out-of-band는 클라이언트가 서버에 정상적으로 주고받는 채널 외에 별도로 채널을 둬서 이루어질 수 있다. out-of-band에서 오는 데이터는 우선순위를 높게 둬서 이곳으로 오는 데이터를 우선 처리할 수 있도록 한다.
다른 방식으로는 채널은 하나로 두지만 데이터 헤더의 flag를 둬서 표시할 수도 있다.
Stateless vs Stateful
(1) Stateless server
클라이언트의 상태 정보를 관리하지 않는 서버이다. 현재 연결된 클라이언트와 loosely coupled 된 서버이므로 서버의 상태를 변경하고자 할 때 클라이언트에 영향을 미치지 않는다. 따라서 클라이언트에 따로 통보를 할 필요 없다.
대표적인 예로 원래의 Web server가 있다. 웹서버는 원래 연결된 웹 브라우저에 대한 상태 정보를 저장하지 않는다. request/reply 형태로 요청을 받고 응답하는 것으로 끝난다. 하지만 실제로 클라이언트의 정보를 알 수 있는 형태를 사용한다. 쿠키 같은 정보를 통해 클라이언트의 상태를 파악하고 더 나은 서비스를 제공하려고 한다. 이 stateless server가 저장하는 클라이언트 상태 정보는 critical 한 정보는 아니라 없어지더라도 크게 영향을 미치지 않는다. 예를 들어 웹 서버가 클라이언트의 log 정보를 기록한 것이 없어진다 하더라도 요청된 request를 처리하는데 크게 영향을 주지 않는다.
(2) Stateless server with soft state
Stateless와 stateful의 중간에 있는 것이다. 클라이언트의 정보를 저장하지만 제한된 시간 동안만 클라이언트의 상태 정보를 유지한다. 해당 시간이 지나면 정보를 버린다. 해당 시간 동안은 서버가 자신의 상태 정보를 바꾸면 클라이언트에게 통지를 해준다. 시간이 지나 해당 클라이언트의 상태 정보를 가지고 있지 않다면 서버 정보를 바꾸어도 알려주지 않는다.
단점은 예를 들어 파일 서버에서 클라이언트가 지속적으로 read나 write를 해야 할 때 매번 파일을 open 한 후 다시 close 해야 하므로 성능이 낮아진다.
(3) Stateful server
클라이언트의 상태 정보를 계속해서 가지고 있다. 클라이언트가 끊긴 다음에도 심지어 히스토리 정보를 가질 수 있는 서버이다. 클라이언트가 요청한 서비스를 얼마나 빨리 응답할지에 대한 서비스의 퍼포먼스 측면만 보면 더 좋다.
예를 들어 파일 서버는 어떤 클라이언트가 어떤 파일을 access 하는지 테이블로 유지하고 있다. 클라이언트가 파일에 대해 access하는 동안에는 계속 그 정보가 남아있게 된다. 장점은 클라이언트가 서버에 있는 파일에 대해 read/write operation에 대한 퍼포먼스가 향상된다. 클라이언트가 하나의 파일에 대해 read나 write 지속적으로 요청한다면 stateful server가 성능이 더 좋다. 그 이유는 서버가 클라이언트가 요청한 파일의 상태를 open 한 채로 둘 수 있기 때문이다. 따라서 클라이언트가 read나 write를 지속적으로 요청할 수 있는 것이다. 대신 단점은 서버가 crash가 생기면 테이블에 대한 정보가 날아갈 수 있고 그러면 복구할 때 까다로울 수 있다. fault tolerent 하게 서버를 만들고 싶으면 테이블 정보를 back-up 해두거나 다른 방식을 활용해야 한다.
어떤 서버를 사용할지는 서비스에 영향을 받지 않는다. 특정 서버만 가능한 서비스는 없지만 단지 퍼포먼스에서 차이가 있을 뿐이다. 항상 그런 것은 아니지만 stateful의 경우 보내는 메시지의 사이즈를 줄일 수 있다. stateless의 경우 매번 자신에 대한 정보를 담아서 보내야 하기 때문이다. 서버가 클라이언트에 대한 히스토리 정보가 있다면 더 효과적인 서비스를 줄 수 있다. 추천 시스템이 그런 것이다. 클라이언트의 과거 정보인 히스토리를 활용하는 방법으로 웹 환경에서는 쿠키가 있다. 클라이언트의 과거 상태 정보를 서버가 관리하는 것은 아니고 클라이언트가 처음 서버에 연결해서 요청하면 서버가 최초의 응답을 하면서 마지막에 쿠키 파일을 클라이언트에게 넘겨준다. 쿠키 정보는 클라이언트 측에서 저장한다. 쿠키 안에는 예를 들어 클라이언트가 서버에 어떻게 연결했고 무슨 서비스를 요청했는지 등의 정보가 들어있다. 쿠키는 캐시와 개념이 비슷하지만 사용 체계는 다르다.
'Distributed System > 이론 공부' 카테고리의 다른 글
| 분산시스템) 코드 마이그레이션 (0) | 2020.08.21 |
|---|---|
| 분산시스템) 서버 클러스터 (0) | 2020.08.19 |
| 분산시스템) 클라이언트 (0) | 2020.08.16 |
| 분산시스템) 가상화 (0) | 2020.08.15 |
| 분산시스템) 프로세스와 스레드 (0) | 2020.08.15 |



